SEO для инди-разработчиков: Практическое руководство
Итак есть один бустрап проект, отличный проект и мало клиентов, мое время дошло до SEO.
Вообще бустрап или инди-проект качает очень многие навыки и учит делать больше фокуса на бизнесе (деньгах) и что маркетологи не бездельники и у них тоже сложная работа!
Сейчас будут довольно базовые штуки, которые я узнал и сделал за последние пару дней (недель).
И так пункт первый, домен:
Section titled “И так пункт первый, домен:”Говорят что .com немного лучше, но в целом пофиг какой, если не новый - то даже лучше -репутация домена и ссылки!
Один из факторов покупки не прибыльных но имеющих потенциал проектов (доменов в том числе) в легкости их раскачки, если знаешь что делать.
У нас ASO.dev - урвали магически за 98 баксов (или очень близко к этому)
Дальше делаем сайт. Нам нужна SEO, так что нужен серверный рендеринг - все разговоры, что гугл умеет парсить js - фигня, так как иногда может, но вообще не любит, поэтому не надо. Можно взять какой-то тяжеловесный SSR для react или Angular, но мы выбрали супер классный, быстрый и простой astro.build, у них кстати хватает простых и сложных шаблонов, но в итоге после экспериментов мы взяли их Starlight, немного переделав первую страницу (там надо скопировать к себе исходник компонента Hero.astro) и override Head.astro.


Я от него в восторге, мы уже даже переписываем сайт нашего плеера meows.app так как динамический рендеринг на базе ответа от API у него работает супер, а переписать с нуля попросили знакомого джуна за небольшие деньги - ему практика и реальный проект, а у нас более быстрый и простой сайт на тех же технологиях что и основной проект, так как Angular 14 уже не огонь, даже с Universal рендеринг (ох, как давно это было) - пример с astro.build (в процессе разработки).
Довольно неплохо вышло, раньше картинки мы жали через TinyPNG (вручную или через API и скрипт от GPT), но сейчас просто стандартными средствами astro.build
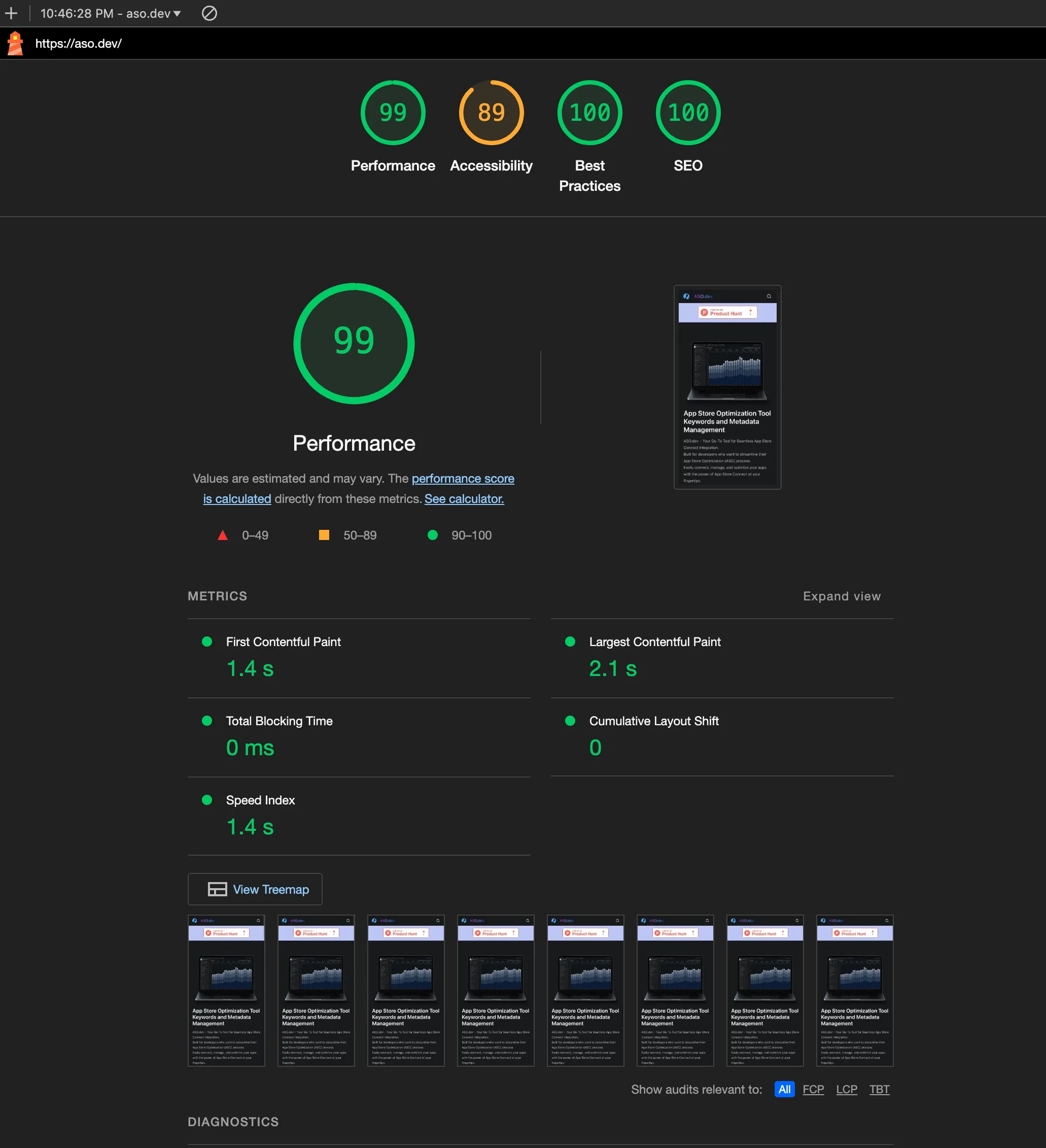
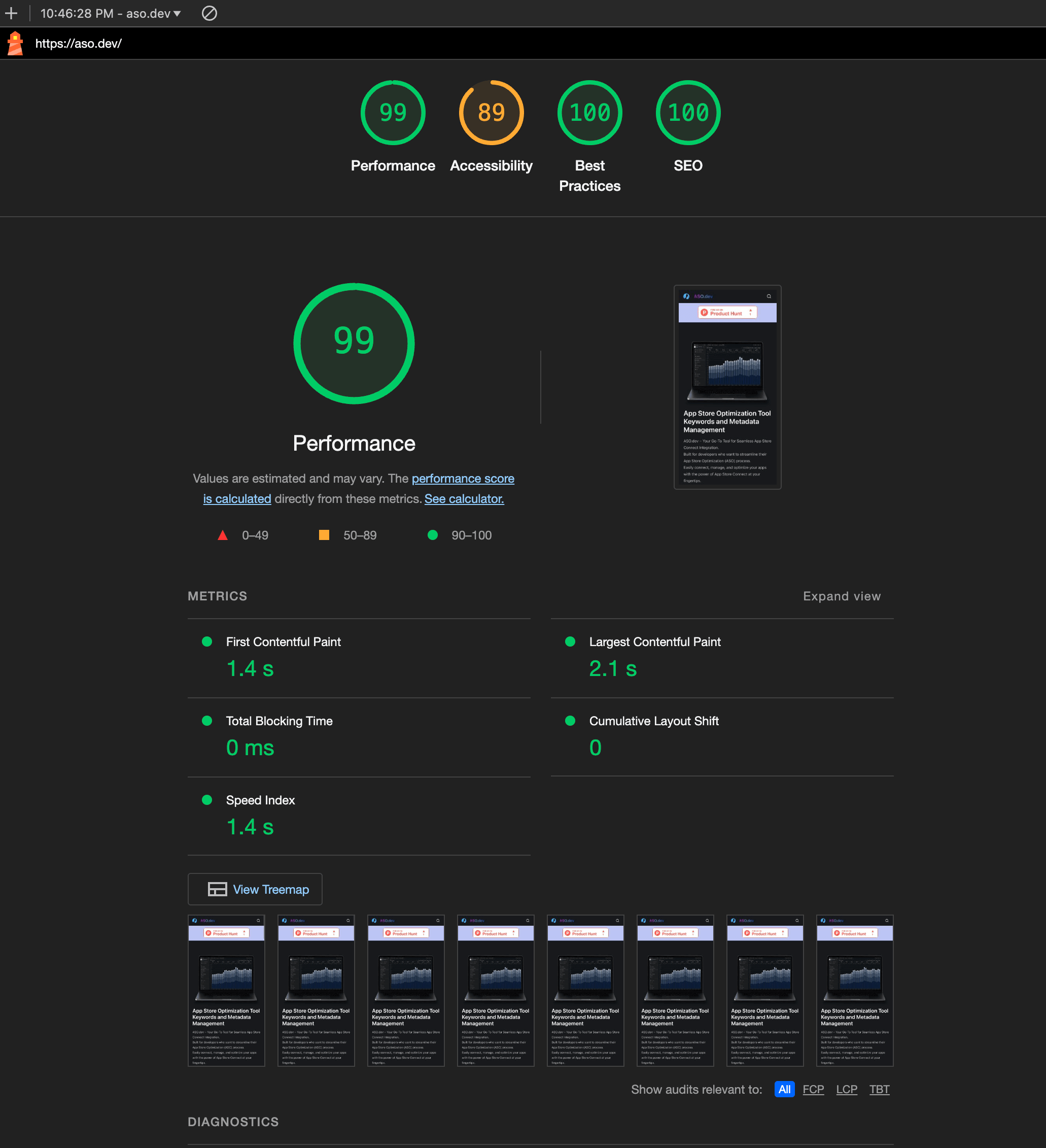
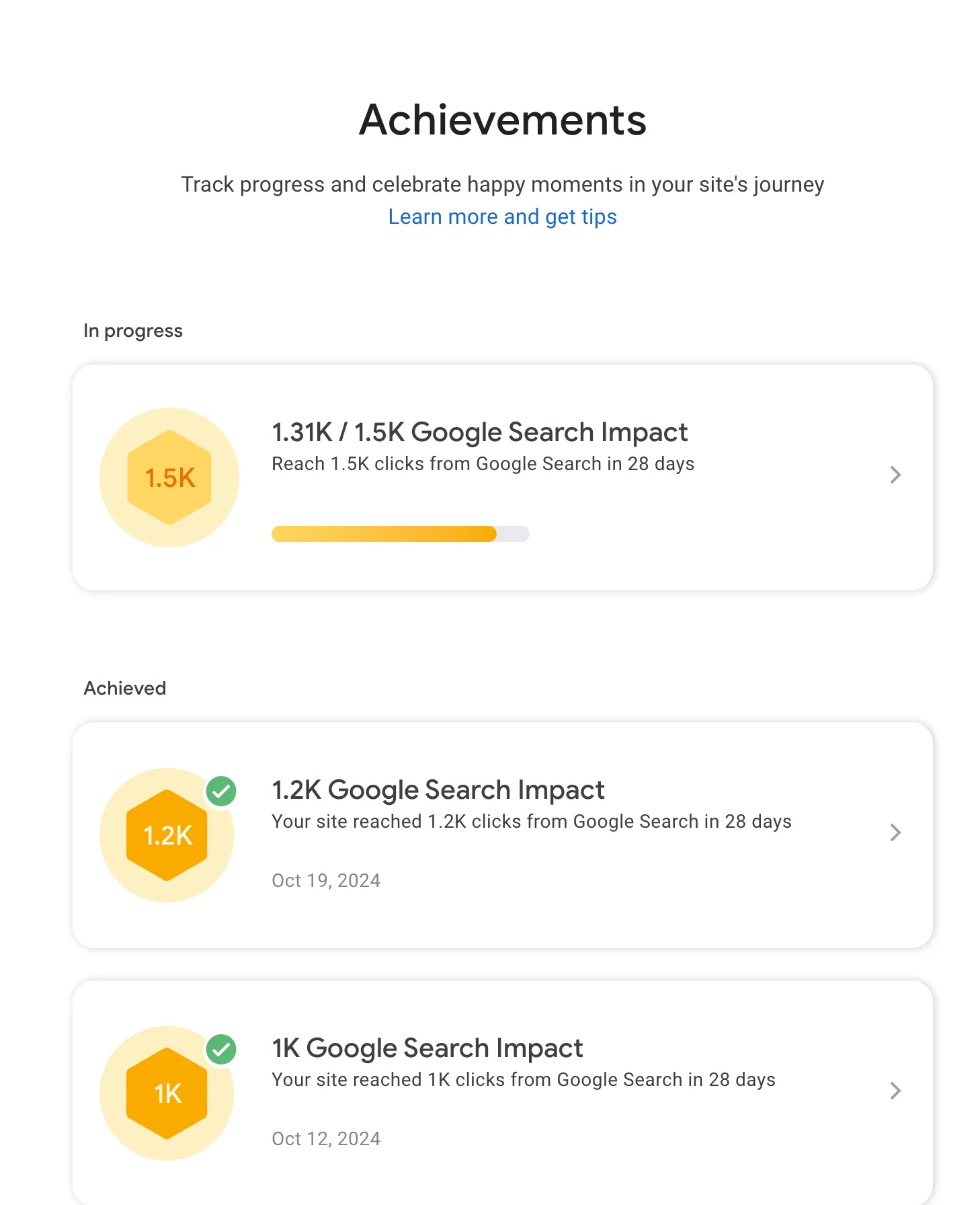
Google search console
Section titled “Google search console”Дальше база - надо зайти и добавить Google Search Console, там можно увидеть свою индексацию, ошибки и получать ачивки (достижения), а их публиковать в X aka Twitter
https://search.google.com/search-console
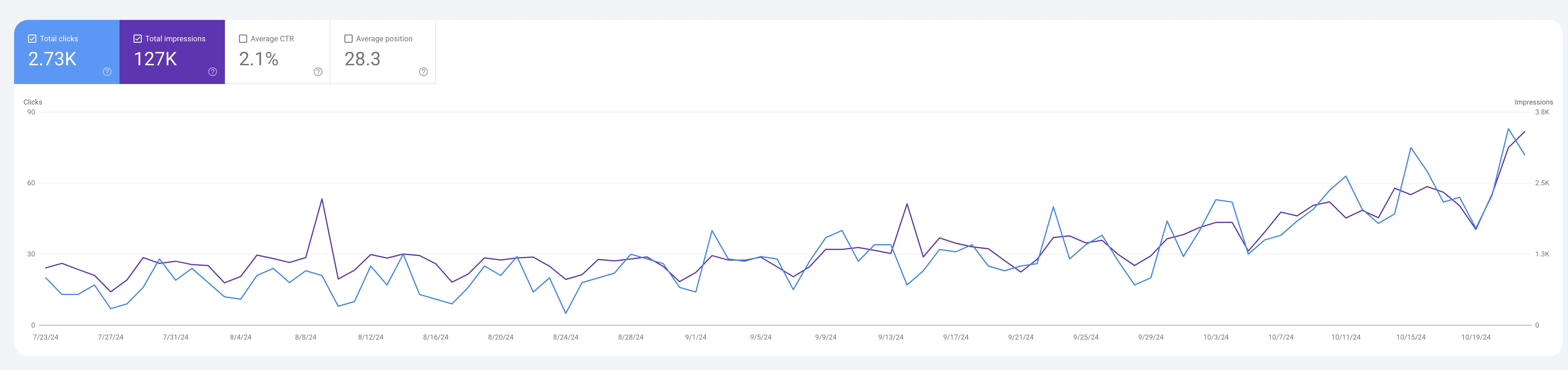
Инструментов на самом деле очень много, я пока пользуюсь двумя бесплатными
Ahrefs
Section titled “Ahrefs”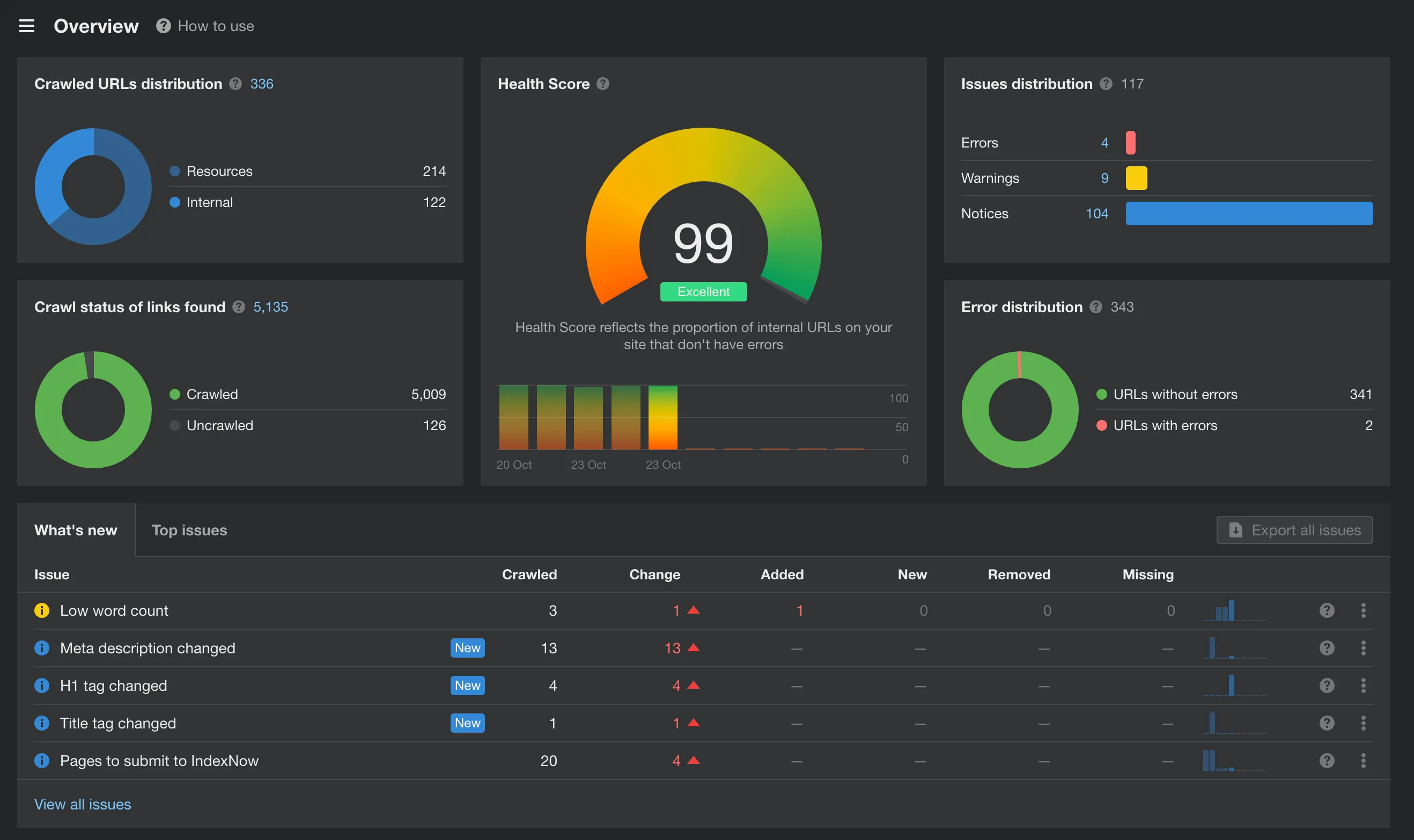
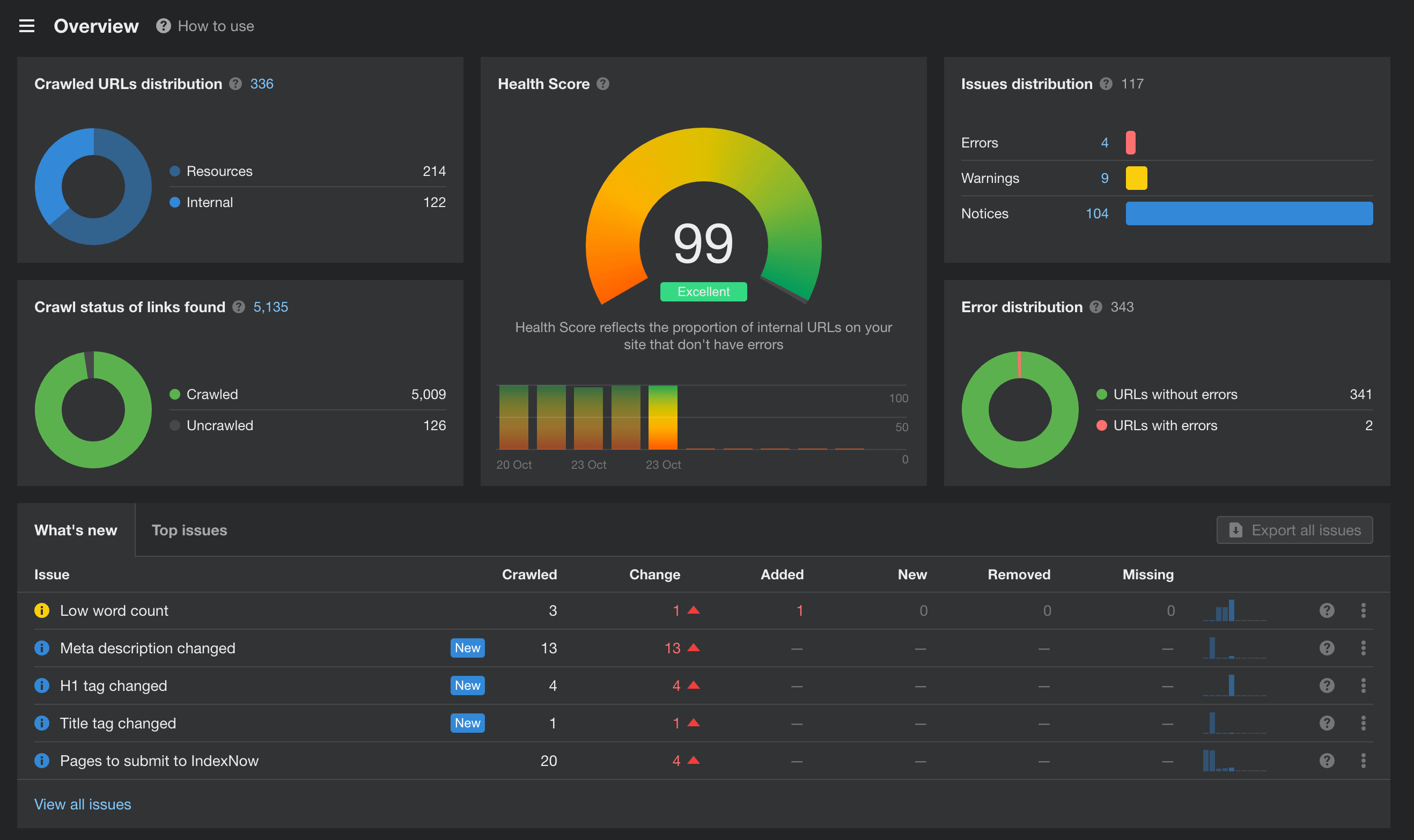
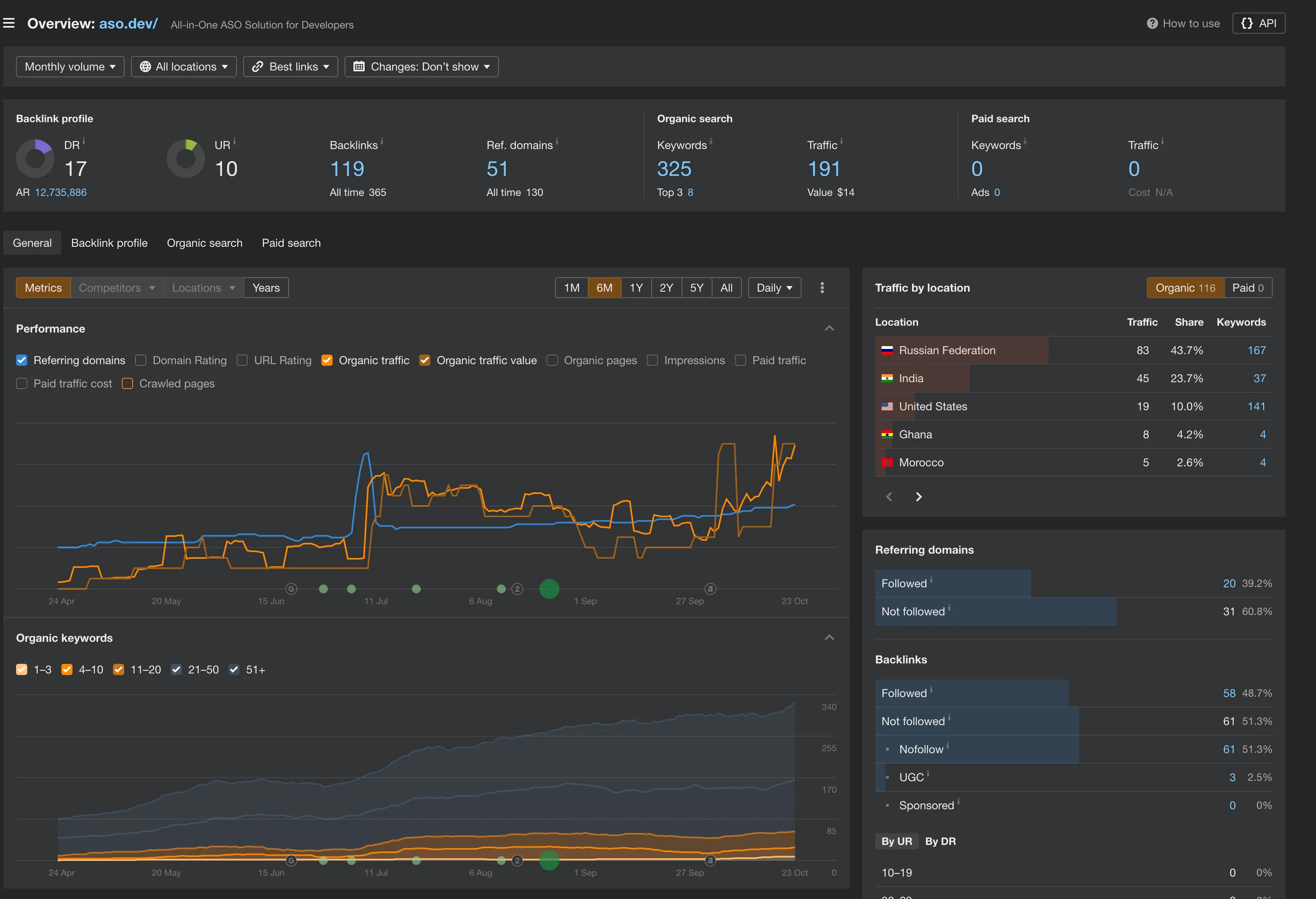
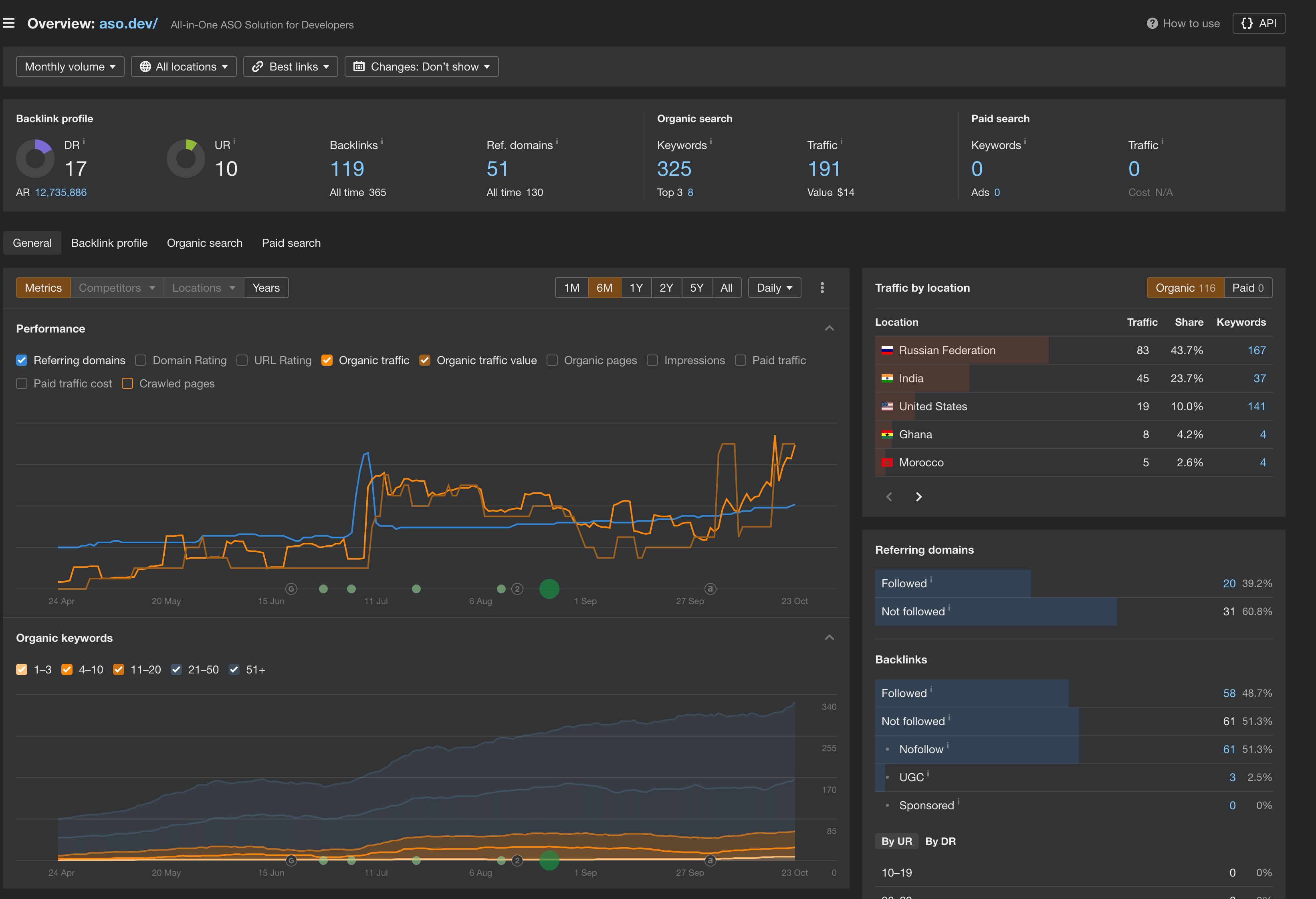
Мне он очень понравился тем что там есть 10к запросов к сайту и анализ всех ваших страниц по ошибкам (закрыть все не получится, но сокращаем до минимума).
Именно этот инструмент дал мне наибольшее количество правок.
Улучшения и ошибки
Section titled “Улучшения и ошибки”Исправление длины title и description страницы
Section titled “Исправление длины title и description страницы”Для title необходимо 50-60 символов, для description 110-160, в структуре мета информации страниц (.md файлов) я добавил их как
seo: seo_title: "All-in-One ASO Solution for iOS Developers, marketing" seo_description: "ASO.dev is ultimate tool for App Store Optimization (ASO) with App Store Connect integration.Manage,optimize,grow your apps effortlessly with powerful features"А дальше попросил gpt написать bash скрипт проверки этих файлов, с 30-ой попытки он таки смог (все равно быстрее, чем сделал бы я на bash)
#!/bin/bashdivider="-----------------------------------"
# Function to check the length of seo_title and seo_descriptioncheck_seo_params() { local file=$1 local in_seo_block=false local seo_title="" local seo_description=""
while IFS= read -r line do # Look for the start of the seo block if [[ "$line" =~ ^seo: ]]; then in_seo_block=true fi
# If inside the seo block, search for seo_title and seo_description if [[ "$in_seo_block" = true ]]; then # Search for seo_title if [[ "$line" =~ seo_title:[[:space:]]*\"(.*)\" ]]; then seo_title="${BASH_REMATCH[1]}" fi # Search for seo_description if [[ "$line" =~ seo_description:[[:space:]]*\"(.*)\" ]]; then seo_description="${BASH_REMATCH[1]}" fi fi
# If the seo block ends (new block or end of file), stop reading if [[ "$in_seo_block" = true && "$line" =~ ^[^[:space:]] && ! "$line" =~ ^seo ]]; then in_seo_block=false fi done < "$file"
local have_errors=false
# Check if seo_title is present and valid if [[ -z "$seo_title" ]]; then echo $divider echo $file echo "seo_title: Empty or not found" have_errors=true elif [[ ${#seo_title} -lt 50 || ${#seo_title} -gt 60 ]]; then echo $divider echo $file echo "seo_title: Length ${#seo_title} (50 <> 60): '${seo_title}'" have_errors=true fi
# Check if seo_description is present and valid if [[ -z "$seo_description" ]]; then if [[ $have_errors = false ]]; then echo $divider echo $file fi echo "seo_description: Empty or not found" have_errors=true elif [[ ${#seo_description} -lt 110 || ${#seo_description} -gt 160 ]]; then if [[ $have_errors = false ]]; then echo $divider echo $file fi echo "seo_description: Length ${#seo_description} (110 <> 160): '${seo_description}'" have_errors=true fi
# Print divider only if there are no errors # if [[ $have_errors = false ]]; then # echo $divider # fi}echo $divider# Recursive search for all .md and .mdx files in the src/content/docs directoryfind src/content/docs -type f \( -name "*.md" -o -name "*.mdx" \) | while read file; do # Check if the file contains a seo block before proceeding if grep -q "seo:" "$file"; then check_seo_params "$file" fidoneecho $dividerЗапускаем скрипт, переходим в файл, копируем текст в GPT и просим оптимальный title и description, примерно таким промтом:
Write seo_title and seo_description, send the result in English, use best practices and length requirements for seo.Result in the format:`yaml seo_title: "" seo_description: ""`seo_title 50-60 symbols, seo_description 100-160 symbolstext is ...Дальше обновляем все страницы - это супер базово, я понимаю, но лучше чем ничего с одинаковыми данными.
Favicon
Section titled “Favicon”Мы его немного сломали - неприятно, нагенерировал файлов и мета тэгов через RealFaviconGenerator - там же и проверил работу.
Можно еще через websiteplanet.
OG теги
Section titled “OG теги”Я немного пошел в оптимизацию, но до этого я сделал og теги - это такие мета-теги, которые позволяют вашей ссылке в социальных сетях или чатах показывать картинку, описание и вообще давать больше информации чем просто ссылка. Их довольно много, но нужно как минимум og:title, og:description, og:image , он кстати должен быть с абсолютным путем, а все картинки мы отдаем через bunny.net, но я что-то намудрил и они пока отдаются напрямую - DNS у нас на Cloudflare, а хостимся мы в Hetzner с помощью docker и Rancher
application/ld+json
Section titled “application/ld+json”Добавили application/ld+json - не уверен что оно как-то сработает, но вроде прикольно - structured data markup
{ tag: "script", attrs: { type: "application/ld+json", }, content: JSON.stringify({ "@context": "https://schema.org", "@type": "WebSite", url: canonical?.href, headline: ogTitle, description: page_description_seo, image: [imageUrl?.href],
mainEntity: { "@type": "Article", headline: page_description_seo, url: canonical?.href, dateModified: data?.lastUpdated, image: [imageUrl?.href], author: { "@type": "Organization", name: "ASO.dev", url: "https://aso.dev", }, publisher: { "@type": "Organization", name: "ASO.dev", logo: { "@type": "ImageObject", url: fileWithBase(config.favicon.href), }, }, }, }), },Создали кастомную страницу 404, по умолчанию все идет в index page и это считается ошибкой - не знаю насколько это серьезно влияет, но она помогает найти неправильные ссылки.
Настройка в мете:
// 404if (canonical?.pathname === "/404") { headDefaults.push({ tag: "meta", attrs: { name: "robots", content: "noindex", }, });}Настройка в nginx конфиге
location / { proxy_redirect off; absolute_redirect off;
proxy_set_header Host $http_host;
try_files $uri $uri/ =404;
# try_files $uri $uri/ /index.html; add_header Cache-Control "no-store, no-cache, must-revalidate, max-age=0"; add_header Pragma "no-cache"; add_header Expires "Thu, 01 Jan 1970 00:00:00 GMT"; } # 404 page error_page 404 /404.html; location = /404.html { root /app; internal; }Pедиректы (перенапраяления)
Section titled “Pедиректы (перенапраяления)”У нас оказалось очень много 301 редиректов, так как мы выбрали чтобы все ссылки были в конце с / , чтобы на https://aso.dev/aso/ и https://aso.dev/aso не получать дублирования, в результате долгой проверки всех ссылок и отчетов - мы их все победили и нашли десяток старых ссылок в коде.
Редиректы для старых ссылок мы поддерживаем в nginx конфиге форматом
# https://aso.dev/app-info/app-info/ https://aso.dev/aso/app-info/ rewrite ^(/ru|/en)?/app-info/app-info/?$ $1/aso/app-info/ permanent;Copilot их кстати хорошо помогает писать.
hreflang
Section titled “hreflang”Добавили x-default для hreflang - не знал что такое нужно
// Link to language alternates.if (canonical && config.isMultilingual) { for (const locale in config.locales) { const localeOpts = config.locales[locale]; if (!localeOpts) continue; const langPostfix = localeOpts.lang === "en" ? "" : localeOpts.lang; headDefaults.push({ tag: "link", attrs: { rel: "alternate", hreflang: localeOpts.lang, href: localizedUrl(canonical, langPostfix).href, }, }); } headDefaults.push({ tag: "link", attrs: { rel: "alternate", hreflang: "x-default", href: localizedUrl(canonical, '').href, }, });}SEMrush
Section titled “SEMrush”https://www.semrush.com/projects/
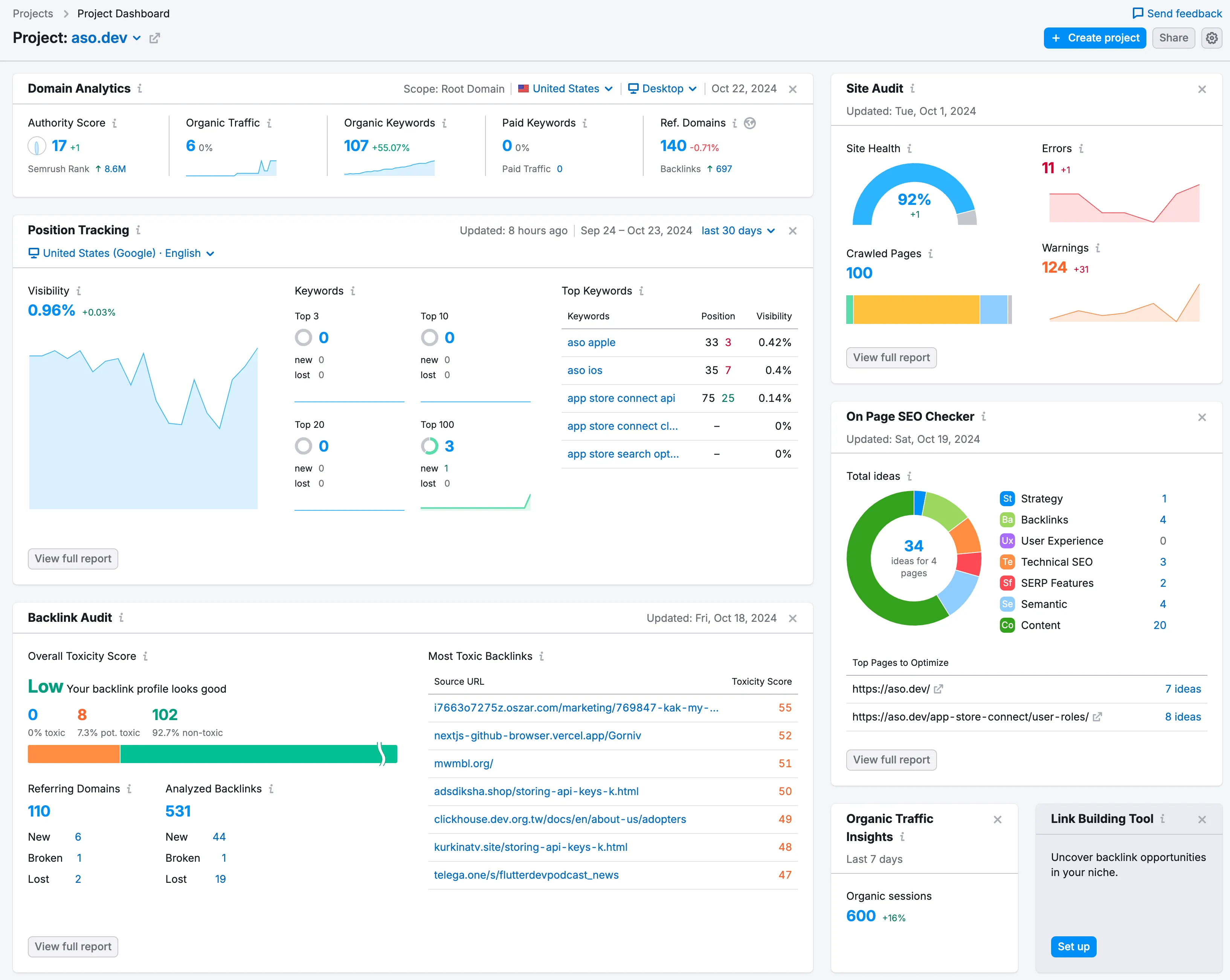
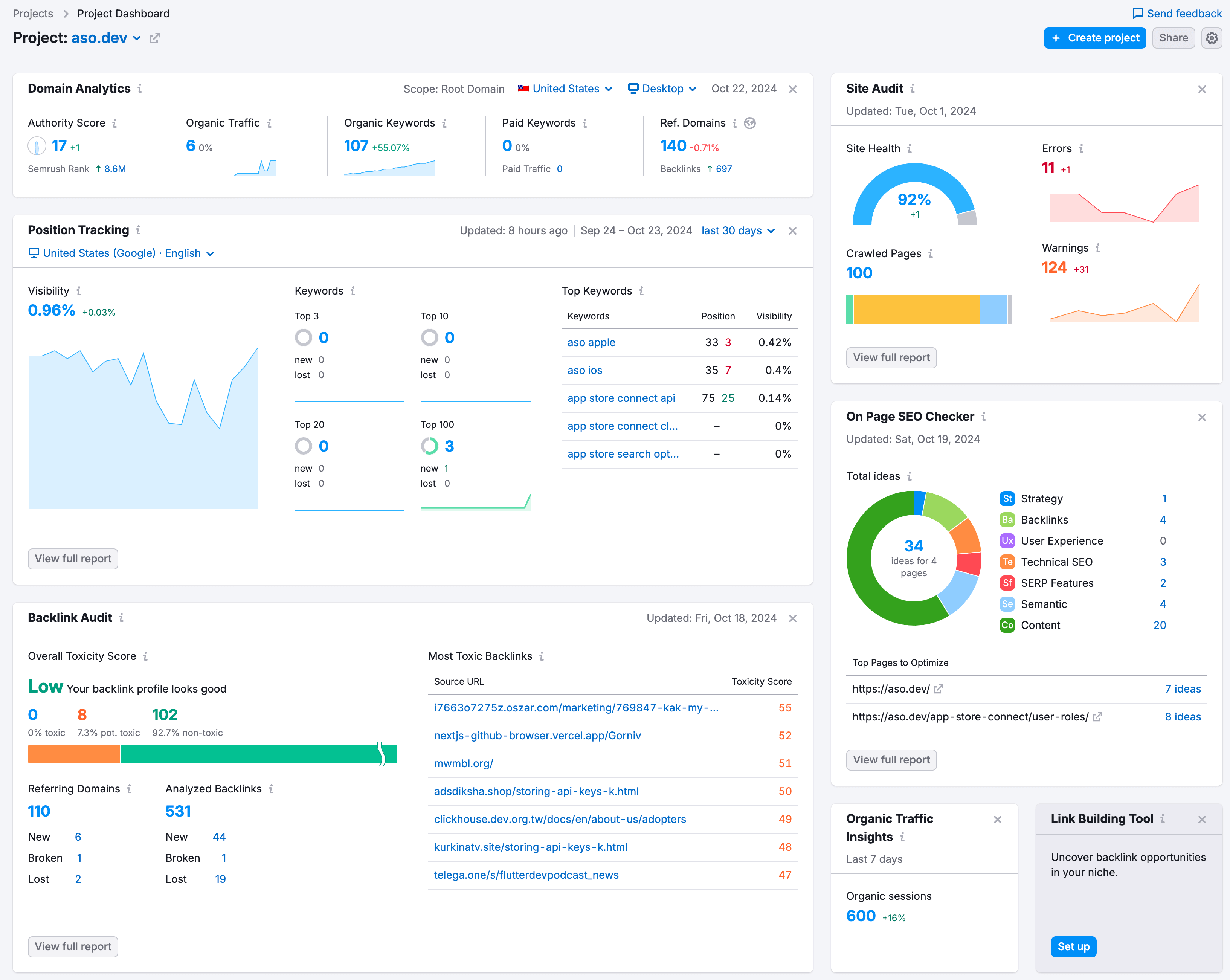
Я с ним более давно, так он как-то проще конвертит в бесплатный тариф, но лимит в 100 проверок и их цены не особо радуют.
Обратные ссылки (Backlink)
Section titled “Обратные ссылки (Backlink)”Это простая и сложная вещь… Вам нужны ссылки на ваш сайт с других сайтов.
Причем если ссылка будет со спам сайта - это плохо (точно не +), а если с NYT - то одна ссылка дает больше бонусов, чем сотни с сайта Васи Пупкина.
Мы пока наращиваем ссылочную массу тем что размещаем наш сайт на куче площадок про стартапы и инди-проекты, нашли Excel файл где сотни ссылок и постепенно его заполняем…
На ProductHunt для получения сильных ссылок полезно - подпишитесь на наш выход, мы его несколько раз уже переносили, но скоро выйдем…
Ну а еще стараемся писать статьи (полезные, а не для галочки).